
올라프의 AI 공부
Knowledge Graph Construction (DSBA 세미나 정리) 본문
Introduction
지식그래프 임베딩(Knowledge Graph Embedding, KGE) Model을 사용하기 위해서는 지식그래프(Knowledge Graph, KG)가 존재해야 한다. 이를 위해 이번 포스트에서는 지식그래프(KG)를 어떻게 구축하는지에 대해 공부하고 정리해보았다.
KG는 지식베이스(Knowledge Base, KB)를 그래프화시킨 데이터라고 생각하면 되는데, 이 때 KB는 (head entity, relation, tail entity) 형태로 존재한다. 이 (h, r, t) 구조를 triplet(또는 triple), fact라고 부른다.
예를 들어 아래 네 가지 triplet이 존재할 때 오른쪽처럼 그래프로 나타낼 수 있으며 이를 Knowledge Graph(KG)라고 부른다.

DSBA 연구실의 Knowledge Graph Construction 영상을 바탕으로 공부한 내용을 정리해보았다. https://www.youtube.com/watch?v=_THQzPiLvyI&t=3221s
Overview
지식 베이스(KB) 데이터가 미리 존재해서 우리가 바로 KG로 바꿀 수 있으면 가장 좋겠지만, 현실적으로 KB 형태로 존재하는 데이터는 많지 않다. 따라서 실무에서는 보통 일반적인 텍스트(Wikipedia 등)를 Information Extraction System을 통해 정형화된 KB 형태로 만들어주고, 이를 KG 형태로 바꾼다.
Knowledge Graph Construction은 Information Extraction System 과정이 어떻게 진행되는지에 대해 배우는 것이다.
Knowledge Graph Construction Steps은 다음과 같다.
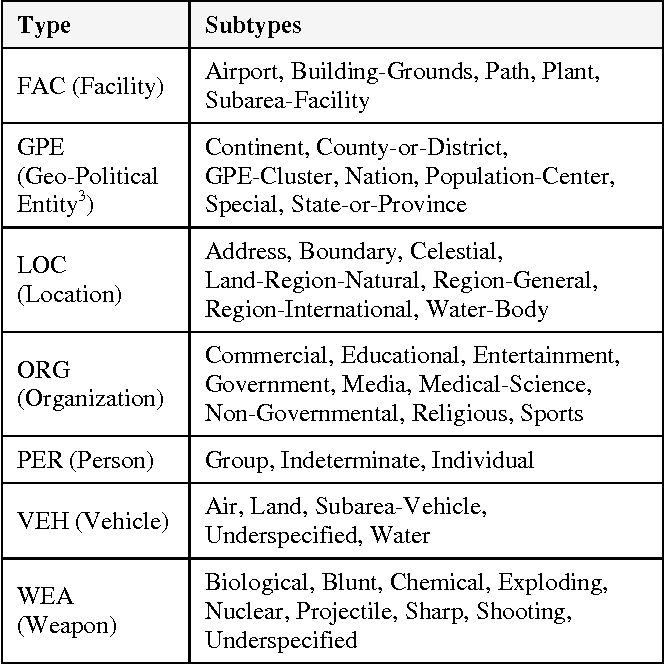
1. Named Entity Recognition (NER) : Entity가 될 수 있는 고유명사 등의 것으로 목적에 따라 정의
2. Relation Extraction (RE) : 구조화되지 않은 일반 텍스트에서 Entity Pair 사이에 Relation을 찾는 Task
=> Information Extraction
3. Event Extraction
4. Entity Linking
5. Coreference Resolution : 특정 Entity를 표현하는 다양한 mention(다르게 표현된 Phrase)들을 연결해주는 Task
6. Knowledge Graph Completion : KG를 완성하기 위한 단계로 missing edges를 찾는 Task
Details
DSBA 영상에서는 이 중에 1,2,5,6에 대해서 더 구체적인 설명을 해주고 있다.
1. Named Entity Recognition (NER)
평가지표 : Precision, Recall, F1-score를 활용해 token 단위의 tagging 성능 평가 수행
- 전통적인 접근 방식
- Rule-based Approaches : 특정 도메인 또는 한정적인 데이터 내에서 특정한 패턴을 규칙으로 태깅
- Unsupervised Learning Approaches
- Feature-based Supervised Learning Approaches
- 딥러닝 접근 방식
- Distributed representations for input -> Context encoder -> Tag encoder

2. Relation Extraction (RE)
이전에는 NER, RE 별개의 task로 진행함. 최근에 NER, RE 한 번에 동작하는 경우가 많음. (아래에서 소개할 GraphRel)
평가지표 : Precision, Recall, F1-score
- 전통적인 접근 방식
- Rule-based Approaches
- Semi-supervised RE
- 조건부 모델 접근 방식 (Discriminative Approaches)
- Classification Model
- Sequential Tagging Model
- 생성 모델 접근 방식 (Generative Approaches)
- Seq2Seq 모델 : autoregressive하게 (s,r,o) 쌍 생성
- T5, BART 등의 모델이 있음.
5. Coreference Resolution
평가지표 : Precison, Recall, F1-score (상황에 따라 기준이 다른 MUC, B3, CEAFe, CoNLL F1 사용)
- Mention Detection (NER 과정에서 수행)
- Mention Clustering
- 최근에는 두 과정을 end-to-end로 해결함. 현재 가장 많이 쓰여지고 있는 모델은 SpanBERT 모델임
- SpanBERT를 통해 Text를 임베딩하고 산출된 Entity들의 표현을 활용하여 클러스터링하는 것
6. Knowledge Graph Completion
KG에 대한 두 가지 가정이 존재한다.
Closed World Assumption (CWA), Open World Assumption (OWA)인데 내가 KG를 완벽하게 이해하고 표현했으면 전자, 아닌 경우에 후자로 나눠진다. 대부분의 경우에서 fact를 다 담아내지 못하는 경우가 많기 때문에 OWA를 따르고 있다.
이 때 우리가 알지 못하는 Missing edges를 찾는 것이 하나의 테스크이다. 이를 위한 subtasks들이 몇 가지 존재한다.
- Subtasks
- Entity Prediction : (s,r,?) 또는 (?,r,o)를 입력하여 적절한 entity를 예측
- Relation Prediction : (s,?,o)를 입력하여 적절한 relation type을 예측
- Link Prediction : Node 간 Missing edges 예측
- 접근 방식
- Embedding based : (s,r,o) 각각을 Embedding한 결과를 활용하여 KGC 수행
- Embedding 기준으로 Entity, Relation, Link prediction 후보들의 score를 산출하고 rank에 따라 output을 산출함.
- TransE, TransR 등의 방식이 해당됨.
- Relation Path Reasoning : KG에서는 Composition Relation이 성립
- Random Walk Inference를 주로 사용함.
- Rule-based : Tail에서 Head Entity로 가는 logical rule를 활용해 새로운 relation을 탐색
- Rule mining tule로 AMIE, RLvLR, KALE* 등을 활용함.
- Triple classification-based : GNN 등을 활용한 Embedding 기준으로 특정한 fact의 embedding을 구해 참, 거짓인지 이진분류를 수행
- Embedding based : (s,r,o) 각각을 Embedding한 결과를 활용하여 KGC 수행
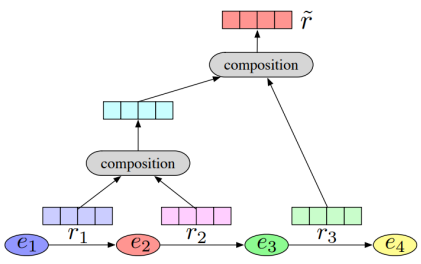

Composition Relation은 아래의 식을 의미한다.
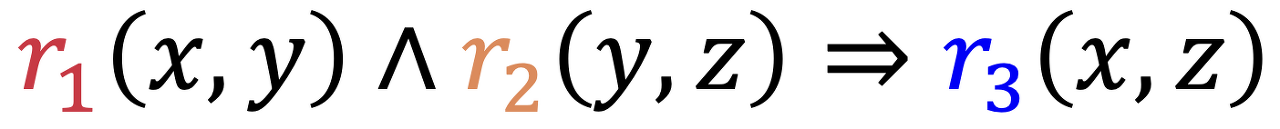
GraphRel
이후에 앞서 잠시 언급한 Named Entity Recognition(NER)과 Relation Extraction(RE) 방법을 한 번에 시행하는 딥러닝 방법론 중 중요한 베이스라인 모델인 GraphRel 모델을 소개한다.
'GraphRel : Modeling Text as Relational Graphs for Joint Entity and Relation Extraction' 논문(ACL2019)은 오늘(2023.04.27) 기준 291회 인용된 유의미한 논문이다. 성능이 높진 않지만 NER과 RE를 한 번에 수행한 초창기 논문이라는 점에 의의가 있다. 또한 Entity Overlap을 고려한다는 점에서 의의가 있다.
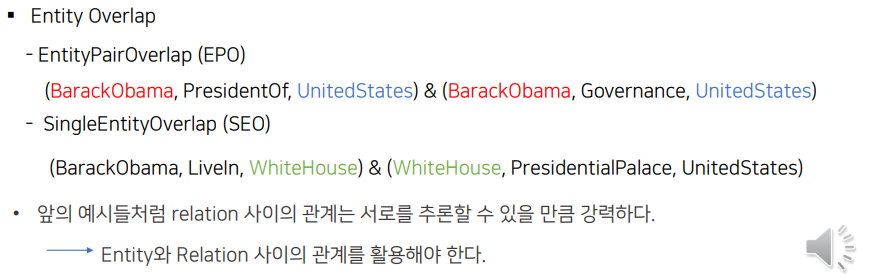
- Entity & Relation extraction 과정에 Bi-LSTM, GCN을 적용하여 시, 공간적 정보를 학습시켰다.
- Entity Extraction과 Relation Extraction을 end-to-end로 수행하였다.
- 1st-phase에서는 entity-relation 사이 관계를 학습하고, 2nd- phase에서는 Entity extraction과 Relation extraction을 수행한다.
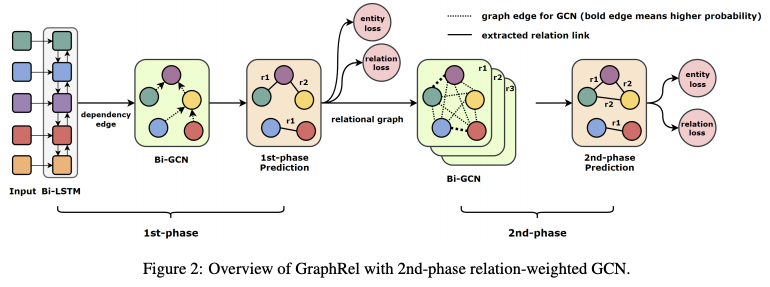
Phase 1
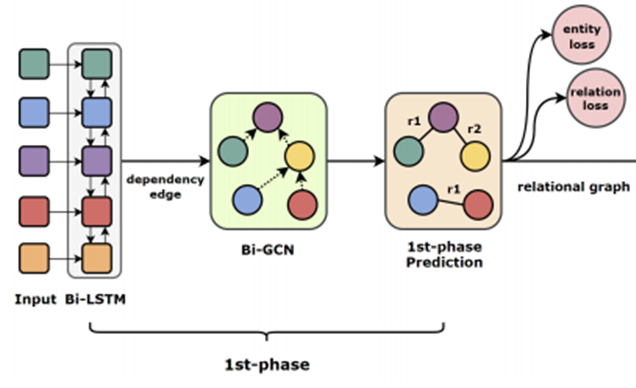
input : POS tagging이 포함된 한 문장씩의 text
- Bi-LSTM
- 문장의 각 단어가 Bi-LSTM의 input으로 사용되어 각 단어의 POS와 단어를 연결해 input으로 넣는다.
- 사전학습된 Glove를 통해 임베딩
- Bi-LSTM으로 각각 시점의 시간적 feature 학습
- 이후 그래프를 사용하기 위해 Bi-LSTM을 통해 나온 output을 그래프 형태로 강제로 만들어줌.
- HOW?!
- Pos tagging의 Dependency Parser(예시: A가 B를 수식한다 등의 수식 관계)를 그대로 활용해 인접행렬(Adjacency Matrix)을 대체해 사용함
- 인접행렬로 만들어진 그래프에서 각 node의 representation은 Bi-LSTM에서 학습한 것을 그대로 활용함
- Bi-GCN
- 양방향 GCN를 통해 node 간 Regional feature를 학습한다.
- Bi-LSTM에서 학습된 representation으로 초기화함
- 양방향이기 때문에 Directed graph로 이웃하는 node에 대해 양방향 별도로 propagate함. (그렇다면 undirected graph면 그냥 lstm을 써도 될까?)
- 아래 식에서 N(u)는 이웃하는 노드들을 의미함
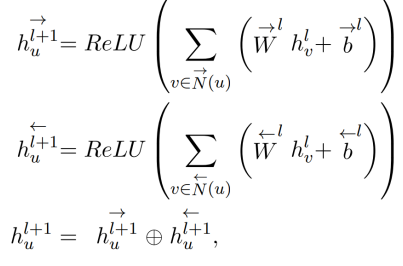
- Extraction of Entities and Relations
- Bi-LSTM과 Bi-GCN으로 Edges를 학습시켰기 때문에 Entities와 Relations을 추출할 수 있다.
- 학습하는 과정동안 Dependency Parser를 통한 인접행렬로 Edge를 학습시켰다. 하지만, 이 과정에서는 학습된 모든 Edge를 무시하고 node representation만을 통해 entity와 relation을 추출한다.
- 그 이유는 Edge는 결국 Dependency Parser에서 말한 수식 관계이기 때문에 그대로 활용할 경우, 새로운 entity 또는 relation이 아닌 기존에 존재하던 entity와 relation에서 Dependency Parser의 수식 관계를 재생산할 것임.
- 모든 단어에 대해 1-layer LSTM을 통해 Entity Classification 수행
- Categorical loss, eloss_{1p}
- 모든 단어 쌍 (S,O)에 대해 모든 relation 예측 수행
- w1, s2에 대해 relation r의 score
- one-hot vector 정답에 대한 categorical loss, rloss_{1p}

Phase 2
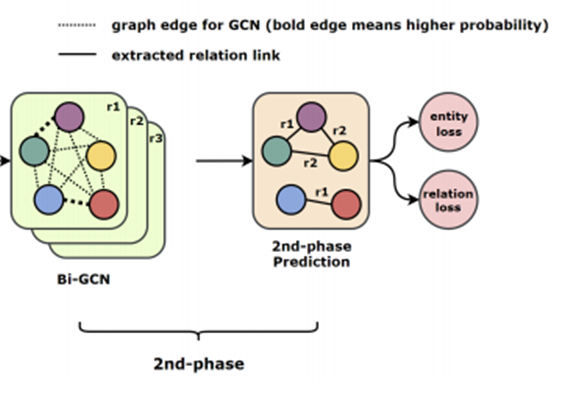
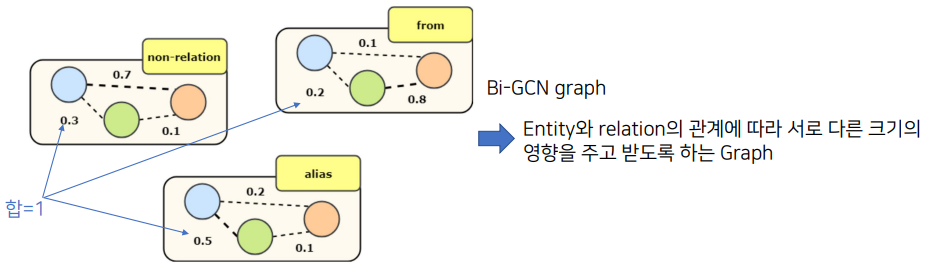
- Relation-weighted Graph
- 1st-phase에서 학습된 w1, w2에 대해 relation r일 확률 P_{r}(w1,w2)를 weight로 하는 그래프
- relation r마다 생성
- Relation마다 생성된 모든 그래프를 결합하여 반영하는 것으로, 2nd-phase에서는 모든 entity와 relation 사이의 관계를 반영할 수 있다.
- 아래 그림처럼 Relation이 'from'과 'alias'만 존재한다고 했을 때, 'non-relation'까지 세 개의 그래프를 그린다. 그리고 파란색(Node1)과 초록색(Node2)의 weight 총합이 1이 되도록 만든다.

- Extraction of Entities and Relations
- 2nd-phase도 1st-phase와 동일하게 Edge를 무시하고 새로 학습된 entity representation에 대해 Entity와 Relation을 추출한다.
- 모든 단어에 대해 1-layer LSTM을 통해 Entity Classification 수행
- Categorical loss, eloss_{1p}
- 모든 단어 쌍 (S,O)에 대해 모든 relation 예측 수행
- w1, s2에 대해 relation r의 score
- one-hot vector 정답에 대한 categorical loss, rloss_{1p}
Training & Inference Detail
- Training
- Entity Extraction : BIESO(Begin, Inside, End, Single, Out) 태깅 방식으로 수행, 모든 단어에 대해 cross-entropy loss 학습
- Relation Extraction : 모든 단어 쌍 w1, w2에 대해 relation r일 확률에 대해 one-hot categorical loss로 학습
- 단어 쌍을 기준으로 relation을 추출하기 때문에 정답의 경우 span이 아닌 단어 단위로 설정
- 예시 : (버락 오바마, 대통령) 사이의 관계를 (버락, 대통령), (오바마, 대통령) 사이의 관계로 해도 정답
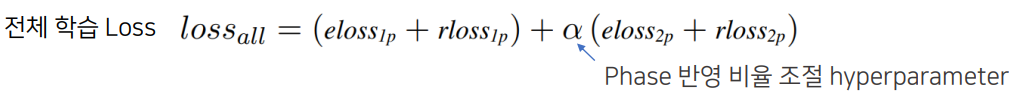
- Inference
- 총 세 가지 방식이 존재한다.
- Head Prediction : 단어 쌍에 대해 최대의 relation만을 산출
- Average Prediction : 동일한 단어 쌍에 대해 다른 relation 산출이 반복될 시, 전체 확률의 평균으로 최대 relation 결정
- Threshold Prediction : 동일한 단어 쌍에 대해 다른 relation 산출이 반복될 시, 각각을 독립적으로 고려해 확률이 threshold를 넘으면 모두 산출
- 실험에서 Threshold 0.0~0.4 구간에서 Precision과 Recall 사이의 Trade-off가 발생하는 것을 보여줌
Experiment
GraphRel은 기본적으로 model relation을 알고 있다는 가정 하에 수행되는 모델이다.
relation의 수만큼 그래프를 그리게 되기 때문에 아래 그림에서 relation의 수가 곧 모델 복잡도가 되는 형태이다.
GraphRel 2nd-stage까지 활용했을 때 성능이 가장 좋았던 것을 통해 Entity와 Relation 사이의 관계를 학습하는 것이 중요하다는 것
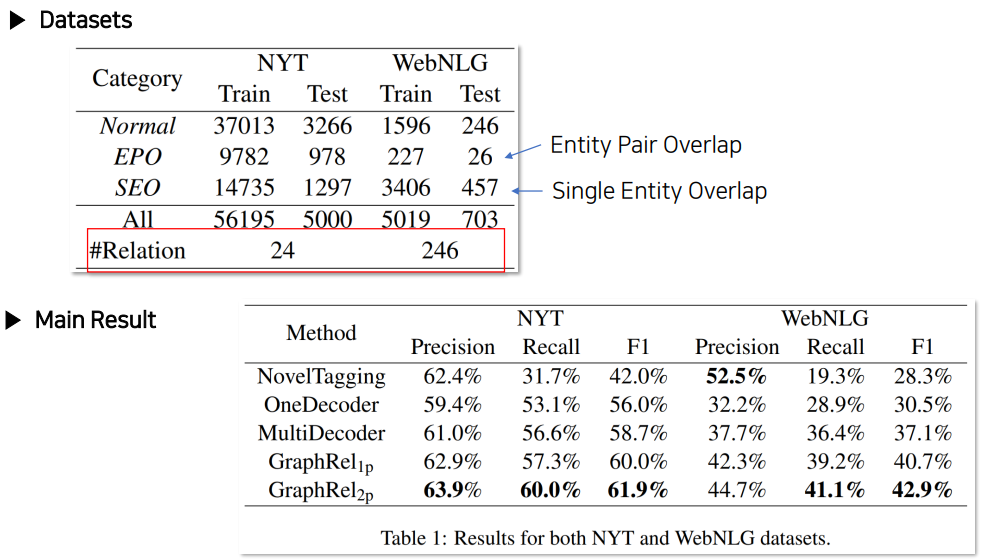
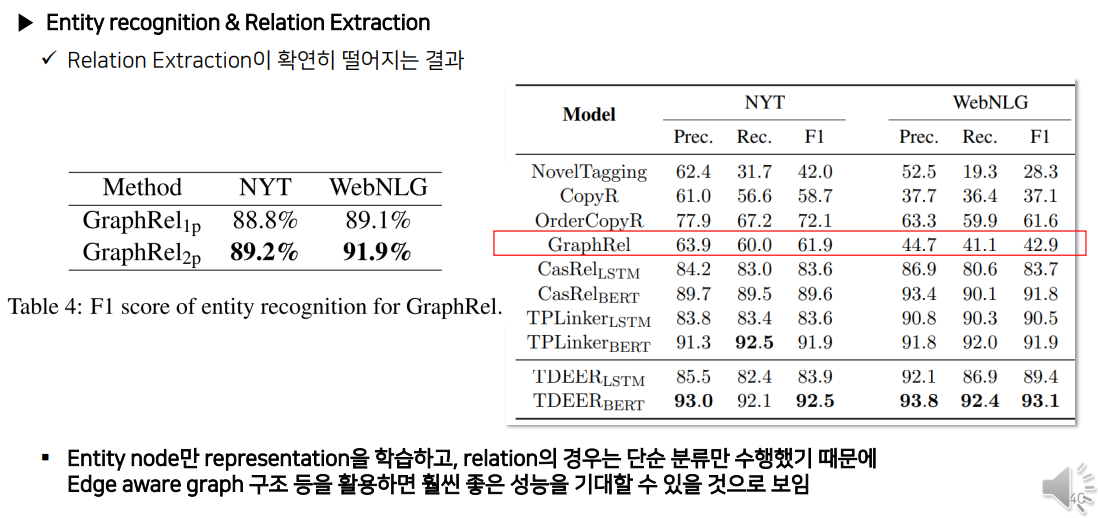
하지만, 아래 그림처럼 최신 타모델들과의 비교했을 때 성능이 떨어지는 것도 확인할 수 있다.
Entity Recognition에서는 F1 score가 좋았지만, Relation Extraction까지 수행한 최종 결과를 보았을 때 성능이 확연히 떨어지는 것으로 보아 Word Embedding에서 비교적 구식 모델인 Glove를 쓰든, 비교적 최신 모델인 T5, BART를 사용하든 성능에는 큰 차이가 없다는 것을 알 수 있었다.
발표자분은 그 이유가 Bi-GCN이 Node Representation만 고려하여 subtask를 진행했기 때문이라고 추측하는데, 최신 논문은 Node뿐만 아니라 Edge에도 Representation을 만들어 학습하기에 더 좋은 성능이 나왔을 것으로 예상하고 있다.
Conclusion

References:
1. DSBA 연구실 Paper Review, Knowledge Graph Construction (노건호 석사과정 발표)
http://dsba.korea.ac.kr/seminar/?mod=document&uid=2616
https://www.youtube.com/watch?v=_THQzPiLvyI&t=2580s


